こんにちは,@PKです.
前回は単回帰分析でしたので,今回は重回帰分析編です.
www.t-kahi.com
散布図・回帰直線の作成,回帰分析結果を出力し,KNIMEで重回帰分析を行う際はどのノードを使うのが良いかを考えてみます.
また,交互作用を考慮した重回帰分析や変数選択を行う場合の例もお示しします.
KNIME Workflowの概要
今回紹介するWorkflowは以下の通りで,重回帰分析に関するいくつかの解析をそれぞれ実行します.

サンプルデータやRの解析については以下を参考にしております.
フリーソフトによるデータ解析・マイニング 第15回 Rと重回帰分析
*このWorkflowでは統計解析向けのR言語を使用するノードを使います.
KNIMEでRを使用する際の基本的な部分は以下を参照ください.
【KNIME】Tukeyの多重検定を「R node」で処理・可視化する - t_kahi’s blog
重回帰分析
重回帰分析のWorkflowを以下に示します.
 サンプルデータは身長,体重,ウエストのデータです.
サンプルデータは身長,体重,ウエストのデータです.
データは「R Source」で読み込みます.
#R Source weight <- c(50,60,65,65,70,75,80,85,90,95) height <- c(165,170,172,175,170,172,183,187,180,185) waist<- c(65,68,70,65,80,85,78,79,95,97) taikei2<- data.frame(weight,height,waist) knime.out <- taikei2
まず,3つの変数の関係性をペアプロットで可視化してみます.
ここでは,ペアプロットを超絶きれいに作成してくれる
GGallyのggpair関数を使いました.
GGallyパッケージのggpair関数を使いこなすための覚え書き : 厚沢部文化財日誌
「R Views」で以下のように書いて実行します.
#R view #install.packages("GGally") library(GGally) ggpairs(knime.in,lower =list(continuous="smooth"))

めっちゃきれいに書ける…
下側がそれぞれの変数の散布図+回帰直線,上側が相関係数,真ん中は密度図です. 体重と身長,体重とウエストはなにか相関がありそうですね…
続いて回帰診断図ですが「R Views」の中は下記通りに作成しました.
【R】回帰診断図(Regression Diagnosis Plots)をggplot2で表示する - t_kahi’s blog
重回帰分析で体重を被説明変数として残りをすべて説明変数としました.
taikei.lm<- lm(weight~.,data=taikei2)
結果は以下の通りです.

続いてKNIMEの線形回帰分析ノードである「Liner Regression Learner」で回帰分析を行います.
設定画面と結果を以下に示します.

設定画面では,ターゲット列(被説明変数)にweightを指定し,Values(説明変数)の部分にはheightとwaistを指定します.
「Liner Regression Learner」右クリック⇒Viewボタンで調整済み決定係数( Adjusted R-squared)を確認すると,Adjusted R-Squared: 0.9872となっており,回帰直線は良く当てはまっています.
続いて,「R snippet」でRのlm関数を使って,単回帰分析の結果を表示させます.
taikei2 <- data.frame(knime.in) taikei.lm<- lm(weight~.,data=taikei2) summary(taikei.lm) knime.out <- summary(taikei.lm)$coefficients

単回帰分析と同じく,「Liner Regression Learner」と「R snippet」どちらを使っても良いと思いますが,データを可視化するなら「R views」で行ったほうがいいでしょう.
特にGGallyのggpair関数はかなりいいと感じました.
交互作用を考慮した重回帰分析
先ほど3つの変数の関係性をペアプロットで可視化した際に,体重と身長,体重とウエストはなにか相関がありそうでした.
このような説明変数同士も関係がありそうな場合は,それらの交互作用も考慮に入れて回帰分析をすることができます.
KNIME Workflowでは今のところ,交互作用を考慮した回帰分析のノードはありません.なので,「R snippet」でコードを書くのが一番簡単だと思います.
lm関数で説明変数の交互作用を考慮するのは2を入れるだけで非常に簡単です.
taikei.lm<- lm(weight~.^2,data=taikei2)
「R views」の回帰診断図は以下の通りです.

「R snippet」で交互作用を考慮した重回帰分析を行います.
taikei2 <- data.frame(knime.in) taikei.lm<- lm(weight~.^2,data=taikei2) #交互作用を考慮 summary(taikei.lm) knime.out <- summary(taikei.lm)$coefficients
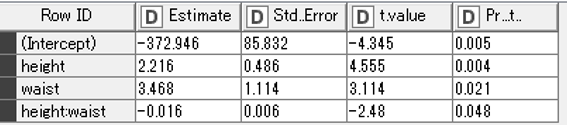
summary関数の結果は「R snippet」⇒右クリック⇒「Views : R Std Output 」で確認できます.
adjusted R-squared: 0.9926 と,交互作用を考慮しない重回帰分析より精度が良くなります.
交互作用を考慮した重回帰分析を全く行わない,というのは考えにくいと思うので,KNIMEで重回帰分析を行う際は,「R snippet 」ノードを使用したほうがいいのでは…と感じました.
step関数を利用して変数選択を行う
最後に重回帰分析の変数選択に関して少しだけ紹介します.

サンプルデータはRのattitudeというデータを用います.
attitude function | R Documentation
「R Source」でサンプルデータを読み込みます.
knime.out <- data.frame(attitude)
まずはペアプロットを「R Views」で作成します.
#R view #install.packages("GGally") library(GGally) ggpairs(knime.in,lower =list(continuous="smooth"))

ratingとcomplaintsなどはよく相関していることがわかりますが,ほとんど相関していない変数もあります.
続いて,「R snippet」でratingを被説明変数,残りを全部説明変数として重回帰分析を行います.
# R snippet attitude <- data.frame(knime.in) attitude.lm <- lm(rating ~ ., data = attitude) summary(attitude.lm) knime.out <- summary(attitude.lm)$coefficients
「R snippet」⇒右クリック⇒「Views : R Std Output 」の結果を以下に示します.
#Views R Std Output Call: lm(formula = rating ~ ., data = attitude) Residuals: Min 1Q Median 3Q Max -10.9418 -4.3555 0.3158 5.5425 11.5990 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 10.78708 11.58926 0.931 0.361634 complaints 0.61319 0.16098 3.809 0.000903 *** privileges -0.07305 0.13572 -0.538 0.595594 learning 0.32033 0.16852 1.901 0.069925 . raises 0.08173 0.22148 0.369 0.715480 critical 0.03838 0.14700 0.261 0.796334 advance -0.21706 0.17821 -1.218 0.235577 --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 7.068 on 23 degrees of freedom Multiple R-squared: 0.7326, Adjusted R-squared: 0.6628 F-statistic: 10.5 on 6 and 23 DF, p-value: 1.24e-05
Adjusted R-squared: 0.6628 なので,あまり当てはまりが良くないですね…
このように複数の変数がある際に,どの変数を使えばいいのかという指標にAICというのがあるそうです.
モデル選択_理論編 | Logics of Blue
このRのstep関数を使うことでAICを基準に変数を選択することができます.
# R snippet attitude <- data.frame(knime.in) attitude.lm <- lm(rating ~ ., data = attitude) attitude.lm2<-step(attitude.lm) summary(attitude.lm2) knime.out <- summary(attitude.lm2)$coefficients
「R snippet」⇒右クリック⇒「Views : R Std Output 」の結果を以下に示します.
#Views R Std Output Start: AIC=123.36 rating ~ complaints + privileges + learning + raises + critical + advance Df Sum of Sq RSS AIC - critical 1 3.41 1152.4 121.45 - raises 1 6.80 1155.8 121.54 - privileges 1 14.47 1163.5 121.74 - advance 1 74.11 1223.1 123.24 <none> 1149.0 123.36 - learning 1 180.50 1329.5 125.74 - complaints 1 724.80 1873.8 136.04 Step: AIC=121.45 rating ~ complaints + privileges + learning + raises + advance Df Sum of Sq RSS AIC - raises 1 10.61 1163.0 119.73 - privileges 1 14.16 1166.6 119.82 - advance 1 71.27 1223.7 121.25 <none> 1152.4 121.45 - learning 1 177.74 1330.1 123.75 - complaints 1 724.70 1877.1 134.09 Step: AIC=119.73 rating ~ complaints + privileges + learning + advance Df Sum of Sq RSS AIC - privileges 1 16.10 1179.1 118.14 - advance 1 61.60 1224.6 119.28 <none> 1163.0 119.73 - learning 1 197.03 1360.0 122.42 - complaints 1 1165.94 2328.9 138.56 Step: AIC=118.14 rating ~ complaints + learning + advance Df Sum of Sq RSS AIC - advance 1 75.54 1254.7 118.00 <none> 1179.1 118.14 - learning 1 186.12 1365.2 120.54 - complaints 1 1259.91 2439.0 137.94 Step: AIC=118 rating ~ complaints + learning Df Sum of Sq RSS AIC <none> 1254.7 118.00 - learning 1 114.73 1369.4 118.63 - complaints 1 1370.91 2625.6 138.16 Call: lm(formula = rating ~ complaints + learning, data = attitude) Residuals: Min 1Q Median 3Q Max -11.5568 -5.7331 0.6701 6.5341 10.3610 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 9.8709 7.0612 1.398 0.174 complaints 0.6435 0.1185 5.432 9.57e-06 *** learning 0.2112 0.1344 1.571 0.128 --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 6.817 on 27 degrees of freedom Multiple R-squared: 0.708, Adjusted R-squared: 0.6864 F-statistic: 32.74 on 2 and 27 DF, p-value: 6.058e-08
調整済み決定係数を見ると,Adjusted R-squared: 0.6864 と若干回帰直線の当てはまりが良くなっています.
重回帰分析に関する処理をいくつかKNIME Workflowで実行してみましたが,細かいチューニングができないので,KNIMEの線形回帰ノードを使うのではなく,Rノードを使用したほうがよさそうです.